suricata 4.0.3 应用层协议检测
suricata中应用层协议检测包含了两种方法,pattern match和probing parser,这里对协议检测的初始化和查找做整理记录。
协议检测 - 初始化
应用层协议检测用到了模式匹配,包括多模匹配和单模匹配,因此首先需要对模式匹配算法进行设定。
- mpm算法注册位置为main -> PostConfLoadedSetup -> MpmTableSetup,里面注册几种mpm算法到全局变量mpm_table中,表中的结构体为MpmTableElmt。这里只是注册了几个mpm算法,并没有对算法添加模式和预处理。下面贴出AC算法的结构体。
- spm算法注册位置为main -> PostConfLoadedSetup -> SpmTableSetup,里面注册两种spm算法到全局变量spm_table中,表中的结构体为SpmTableElmt。这里同样只是注册spm算法,没有添加模式和预处理。两种算法分别是bm和hs,hs需要编译hyperscan。下面贴出BM算法的结构体。
1 | /** |
1 | void SpmBMRegister(void) |
模式匹配算法注册完成后,真正的应用层协议检测初始化位置为 main -> PostConfLoadedSetup -> AppLayerSetup。
可以看到AppLayerSetup代码很少,调用函数功能从名字看也比较明显。唯一有一点不同的是AppLayerParserRegisterProtocolParsers函数内不只注册了应用层协议解析器,也注册了应用层协议检测的内容。本文暂时只关心应用层协议检测部分。
1 | int AppLayerSetup(void) |
AppLayerProtoDetectSetup
这个函数的主要功能是选择出当前使用的spm和mpm算法。并初始化两种算法运行的上下文。
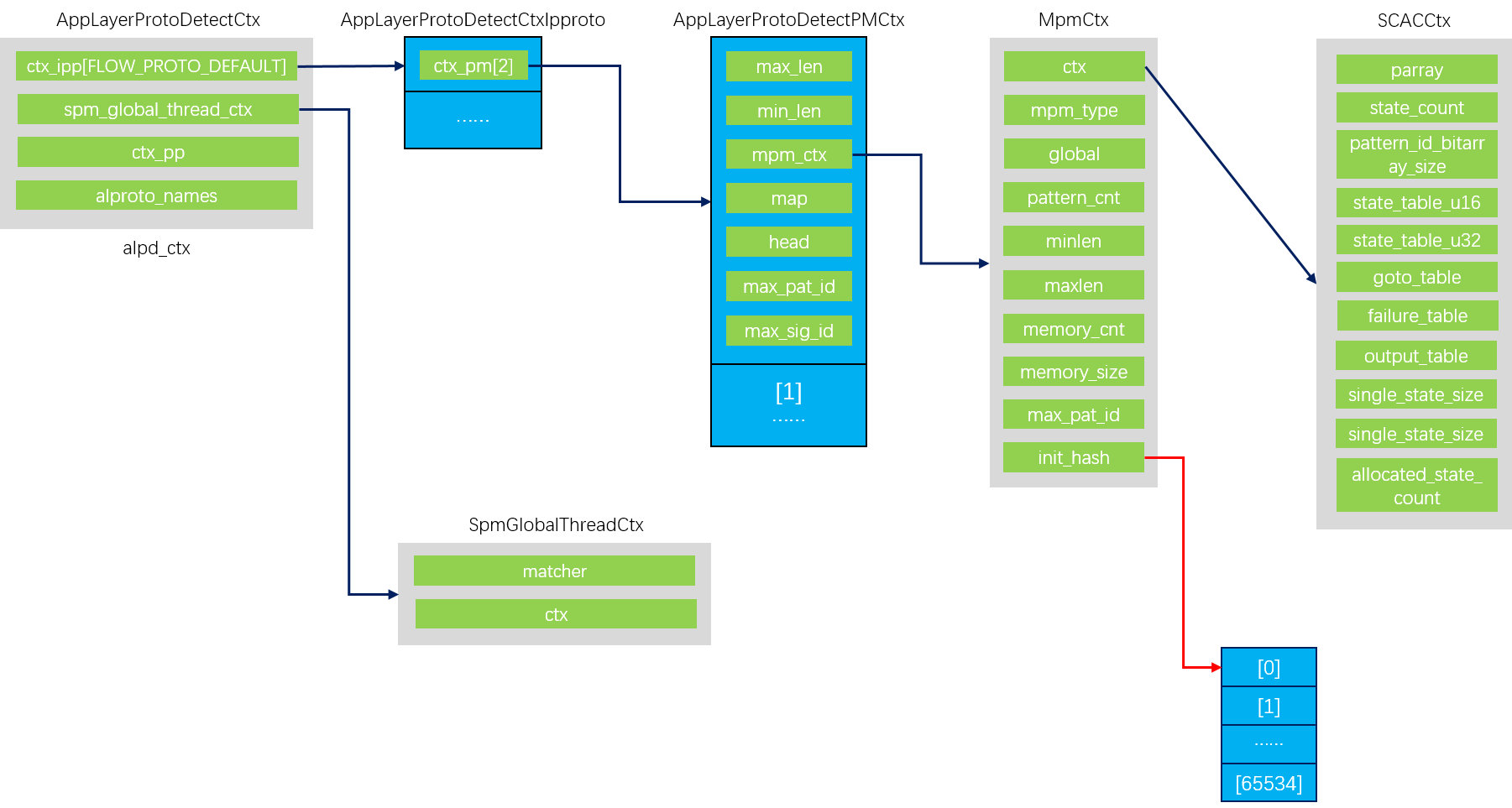
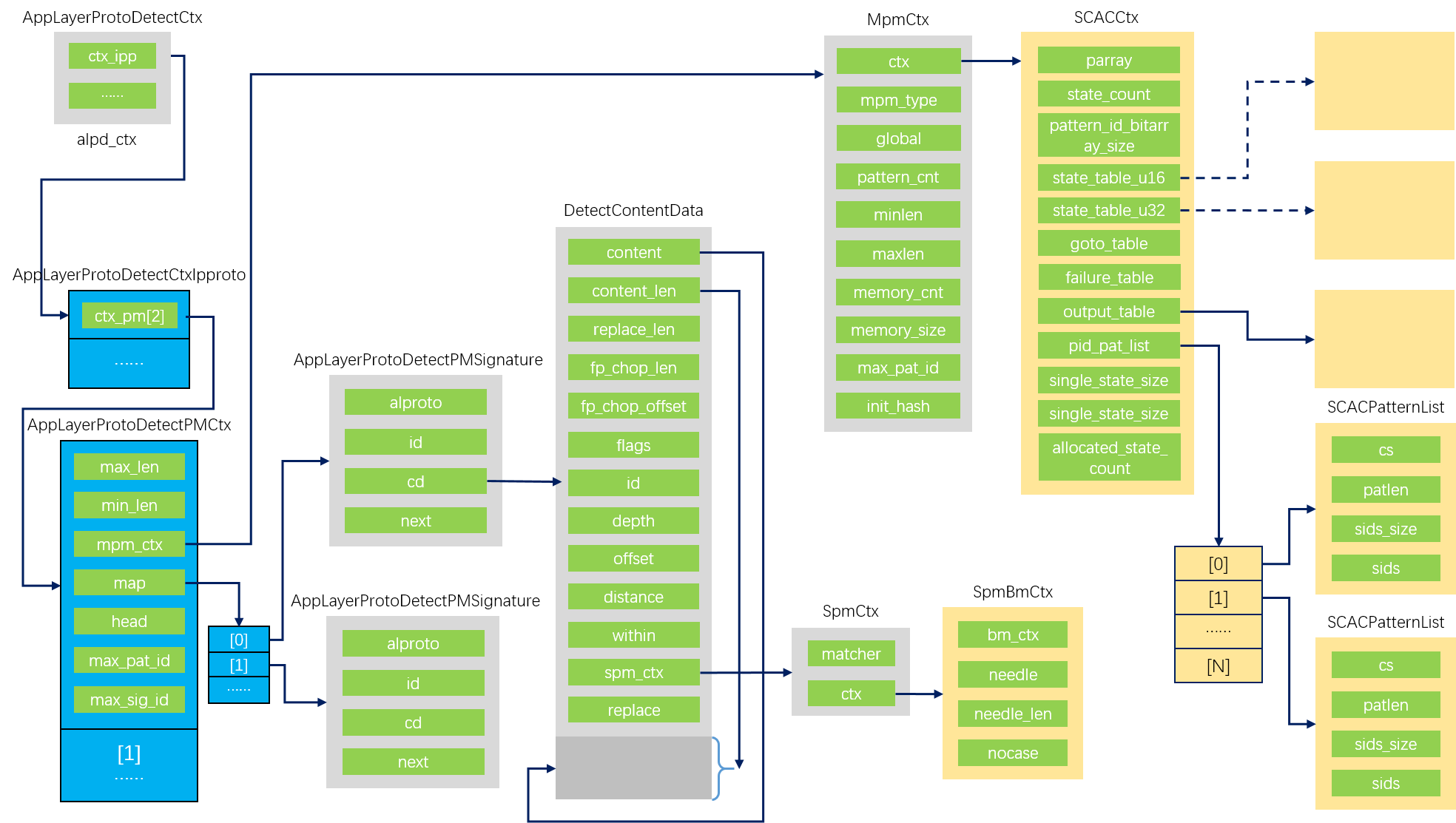
这里出现了静态全局变量alpd_ctx,从名字可以看出这是一个应用层协议检测的上下文变量,实际它的结构也正是包裹了所有的应用层协议检测上下文。
1 | /** |
spm上下文初始化
spm的初始化通用部分仅仅是调用spm算法的函数指针InitGlobalThreadCtx,并将返回的SpmGlobalThreadCtx类型指针赋值给alpd_ctx.spm_global_thread_ctx。
以BM算法为例,实际调用函数BMInitGlobalThreadCtx,这个函数只是分配了SpmGlobalThreadCtx大小的内存,并将spm算法设置为SPM_BM(在BM算法下alpd_ctx.spm_global_thread_ctx的作用仅仅是指明采用的spm算法为BM),然后将内存地址返回。
mpm上下文初始化
mpm的初始化调用mpm算法的函数指针InitCtx,由于有多种四层协议,每种四层协议数据流有两个方向,应用层协议识别的模式在不同四层协议不同方向上不同,因此需要对每种四层协议的两个数据流方向都初始化一个mpm上下文。alpd_ctx.ctx_ipp[i].ctx_pm[j].mpm_ctx中ctx_ipp数组对应多种四层协议,ctx_pm数组对应两个数据流方向,mpm_ctx就是mpm算法的上下文,因此需要对每个mpm_ctx调用函数指针InitCtx。
以AC算法为例,实际调用函数SCACInitCtx。为MpmCtx结构体成员ctx分配SCACCtx大小的内存,这个ctx是未来AC算法做模式匹配时需要的状态表。修改成员memory_cnt、memory_size,分别记录了当前上下文使用的堆上内存块数和内存大小。为成员init_hash分配65535个指针大小的内存,这个成员的作用是作为哈希表在未来插入模式时可以快速去重。
1 | typedef struct MpmCtx_ { |
AppLayerParserSetup
只做了一件事,将AppLayerGetActiveTxIdFuncPtr这个静态全局函数指针赋值为函数AppLayerTransactionGetActiveDetectLog。
AppLayerParserRegisterProtocolParsers
这个函数主要完成三个功能
- 将应用层协议名字符串注册到alpd_ctx.alproto_name数组中。
- 将应用层协议检测的模式注册到alpd_ctx合适的上下文中。
- 注册应用层协议解析相关部分,这里不关注。
pattern match注册
以http协议为例。
首先是协议检测,检查了配置文件节点app-layer.protocols.http.enabled(以dns为例其他协议也可能检测app-layer.protocols.dns.udp|tcp.enabled),如果是yes或detection-only则将协议名字符串“http”注册到alpd_ctx.alproto_names[ALPROTO_HTTP]中并调用HTPRegisterPatternsForProtocolDetection用以注册协议检测需要的patterns模式。这里http协议的检测模式有两种,一种用于toserver方向,使用http method加空格的字符串检测(比如”GET “,这里的空格可以是ascii中的0x20,也可以是0x09)。另一种用于toclient方向,检查服务端返回的http版本号(比如”HTTP/1.1”)。注册检测模式有两个AppLayerProtoDetectPMRegisterPatternCS和AppLayerProtoDetectPMRegisterPatternCI,这两个函数只是AppLayerProtoDetectPMRegisterPattern的一个简单包装,标明了是否大小写敏感(case sensitive,case insensitive)。
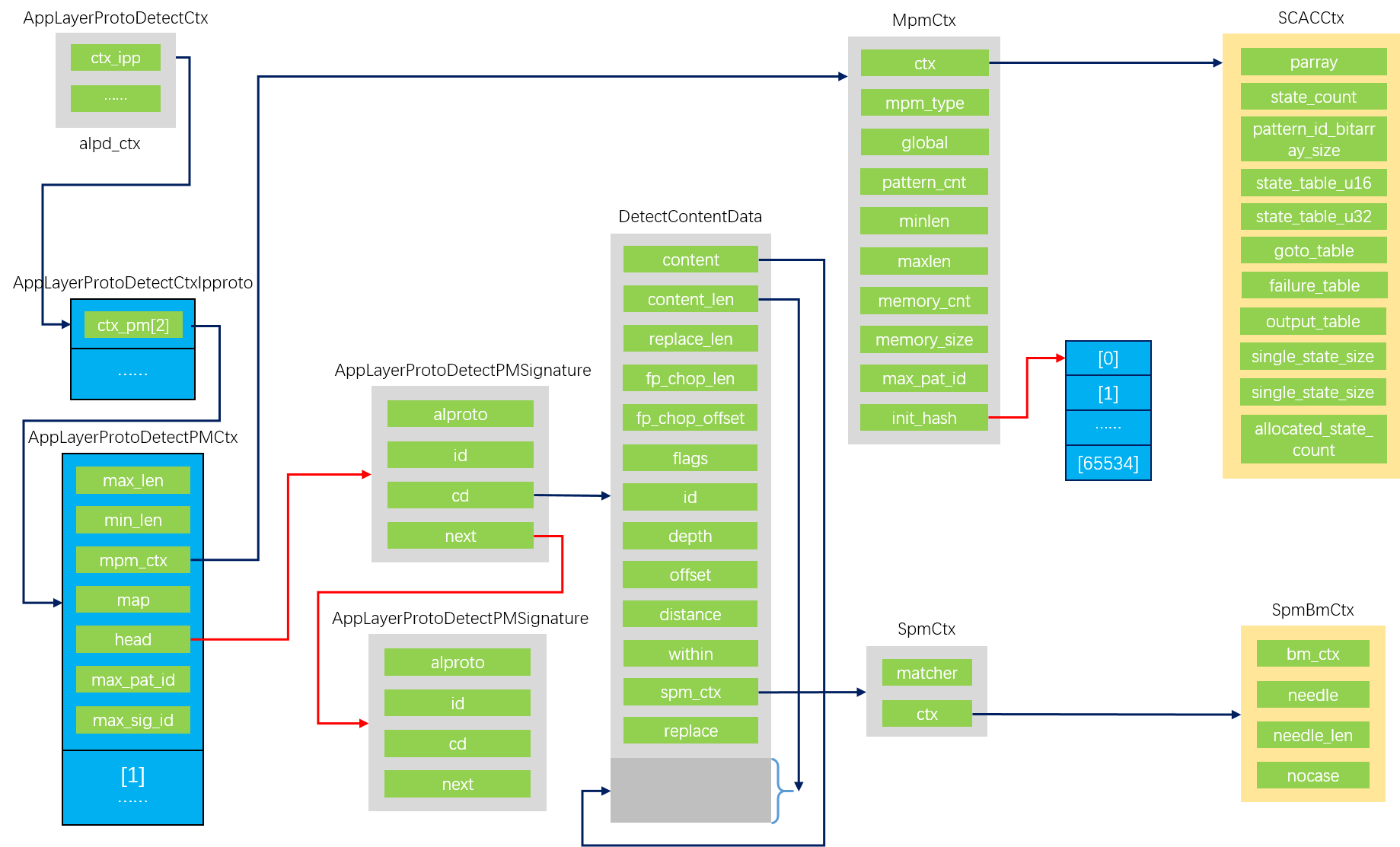
AppLayerProtoDetectPMRegisterPattern
- 首先调用DetectContentParseEncloseQuotes将传入的模式字符串做处理。这里的处理包括替换原模式字符串中代表16进制数的部分为单一字节、将右斜线转义的部分替换为单一字节、检查不合法的未转义的双引号和其他不盒饭的16进制数与转义符号,处理后的模式存入一个新分配内存的结构体DetectContentData中,结构体成员content指向结构体后的内存地址,这里存储了处理后的模式字符串,content_len记录了content指向的实际长度(因为这里的内存可能不再是一个可读字符串了,所以需要指定一个长度)。spm_ctx被赋值为函数SpmInitCtx的返回值,这个函数内部实际调用了当前spm算法结构体的InitCtx函数指针,在BM算法中实际是BMInitCtx,这个函数分配了一些结构的内存保存针对此模式BM算法运行所需要的数据。成员depth、offset、within、distance都置0。将这个DetectContentData实例返回。
- 这个实例(我们称为cd)返回后,根据函数参数修改cd成员depth和offset,这里depth含义为模式匹配查找时所检查的输入最长深度,offset含义为模式匹配查找时从输入的此偏移位置开始查找。
- 如果该模式是大小写不敏感的,重新生成cd成员spm_ctx并为成员flags增加标记DETECT_CONTENT_NOCASE。
- 根据方向取得ctx_pm,根据depth选择更新ctx_pm->max_len和ctx_pm->min_len。
- 将cd填充到一个新分配的AppLayerProtoDetectPMSignature实例中,并标明应用层协议类型。将AppLayerProtoDetectPMSignature实例链接到ctx_pm的head成员上,组成链表。
ps:这里的DetectContentData代表了一个模式,AppLayerProtoDetectPMSignature代表了一个特征,这时模式和特征都还没有分配id。
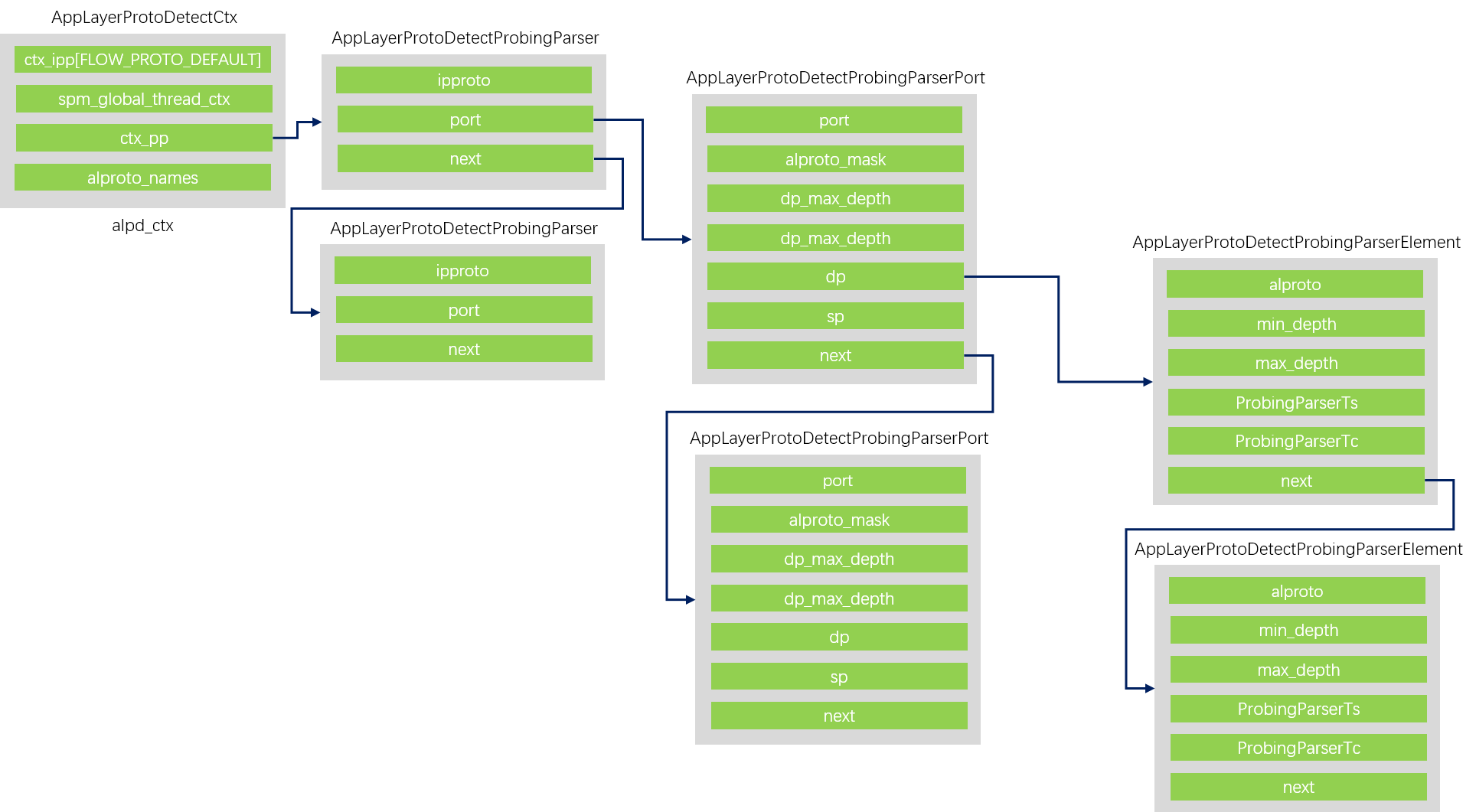
probing parser注册
协议检测除了模式匹配(pattern match),还有一种方式probing parser。http协议检测中没有这种方式,因此以ssl协议为例介绍。(实际运行中注册有ssl的443端口,smb的139和445端口,dns的tcp和udp均包含53端口)
读取配置文件中该协议下的detection-ports段,读取源端口或目的端口字符串并调用AppLayerProtoDetectPPRegister,该函数会解析端口字符串并调用AppLayerProtoDetectInsertNewProbingParser。
- 首先在alpd_ctx.ctx_pp链表上检查是否有符合该四层协议的项,没有则增加。
- 定位该pp成员后,遍历pp中的port链表查找端口号与要注册的端口号一致的port(这个port是一个结构体实例),如果没有则新创建一个并插入到链表中,对端口号0的zero_port做了特殊操作,不过由于实际运行中并没有端口号0注册probing parser,因此不关注这种情况。
- 定位到port后,根据要检查的方向选择dp或sp链表,检查链表下的每个AppLayerProtoDetectProbingParserElement确保没有重复的应用层协议号。创建一个新的pe并填充,插入到port的链表上,同时更新port上的成员dp_max_depth或sp_max_depth。后续又检查当前的端口号是否是0并进行了操作,这里不关注。
可以看到以 四层协议 –> 端口 –> 端口作为源端口还是目的端口 –> 应用层协议 构成了一个四层次关系,在后续probing parser查找的时候也会依据这个四层次关系做定位。
然后是协议解析,与协议检测相关的配置文件节点一样,区别在于只有yes才注册解析功能,no或detection-only会关闭检测功能。这里注册了一堆函数指针到全局变量alp_ctx上,注册时标明了二维数组的四层协议类型和应用层协议类型。这里不多关注。
AppLayerProtoDetectPrepareState
这里针对alpd_ctx下所有四层协议所有方向的AppLayerProtoDetectPMCtx结构(也就是alpd_ctx.ctx_ipp[i].ctx_pm[j])依次调用了三个函数做预处理。
- AppLayerProtoDetectPMSetContentIDs
- AppLayerProtoDetectPMMapSignatures
- AppLayerProtoDetectPMPrepareMpm
AppLayerProtoDetectPMSetContentIDs
这里遍历了ctx_pm中head成员所链接的所有特征,填充max_sig_id(记录了特征的数量),填充max_pat_id(记录了去重后的模式数量),每个模式的成员id记录了这个模式的id(0开始,去重过的。因为不同的特征下可能有相同内容和长度的模式,这里不考虑offset和depth。)
AppLayerProtoDetectPMMapSignatures
这里为ctx_pm中map成员分配了内存,内存空间用作数组,存放特征数量个数的指针。遍历ctx_pm成员head指向的特征链表,为特征的id从0开始赋值,以特征id为数组索引,将map数组的指针指向该特征。遍历过程中断开特征链表的每一个next连接,最后将head连接也置空。遍历每一个特征时,根据特征下模式是否区分大小写调用MpmAddPatternCI或MpmAddPatternCS以将模式添加到mpm算法中。函数运行完毕后,特征链表不再存在,只能从map数组中以特征id为索引定位到特征。
MpmAddPatternCS调用了mpm算法的AddPattern函数指针,MpmAddPatternCI调用mpm算法的AddPatternNocase函数指针,在AC算法中分别对应SCACAddPatternCS和SCACAddPatternCI。这里传递参数的offset和depth都为0,在AC算法实现中可以看到无视这两个限制,但是在mpm查询完毕后会调用spm算法生效offset和depth再次匹配。AC算法中添加模式实际上只是MpmAddPattern的包装,在flags中区分了是否大小写敏感。
MpmAddPattern的功能比较简单,输入参数是多模匹配的上下文(前文ctx_pm内的成员mpm_ctx)、模式内容、模式长度、模式id、特征id和一个flags(这个flags在应用层协议检测时只标记了是否大小写敏感),利用mpm_ctx的成员init_hash对模式快速去重,确保每个模式只生成一个MpmPattern结构实例挂载到init_hash哈希表上,如果出现多个特征对应相同的模式内容,那么扩展MpmPattern结构成员sids记录所有的特征id。
在构造MpmPattern时,同时更新mpm_ctx的一些成员。
ps:其实到目前为止,具体mpm算法无关的结构已经成型了。mpm_ctx成员ctx和init_hash以及MpmPattern结构都是与后续mpm算法预处理有关的。
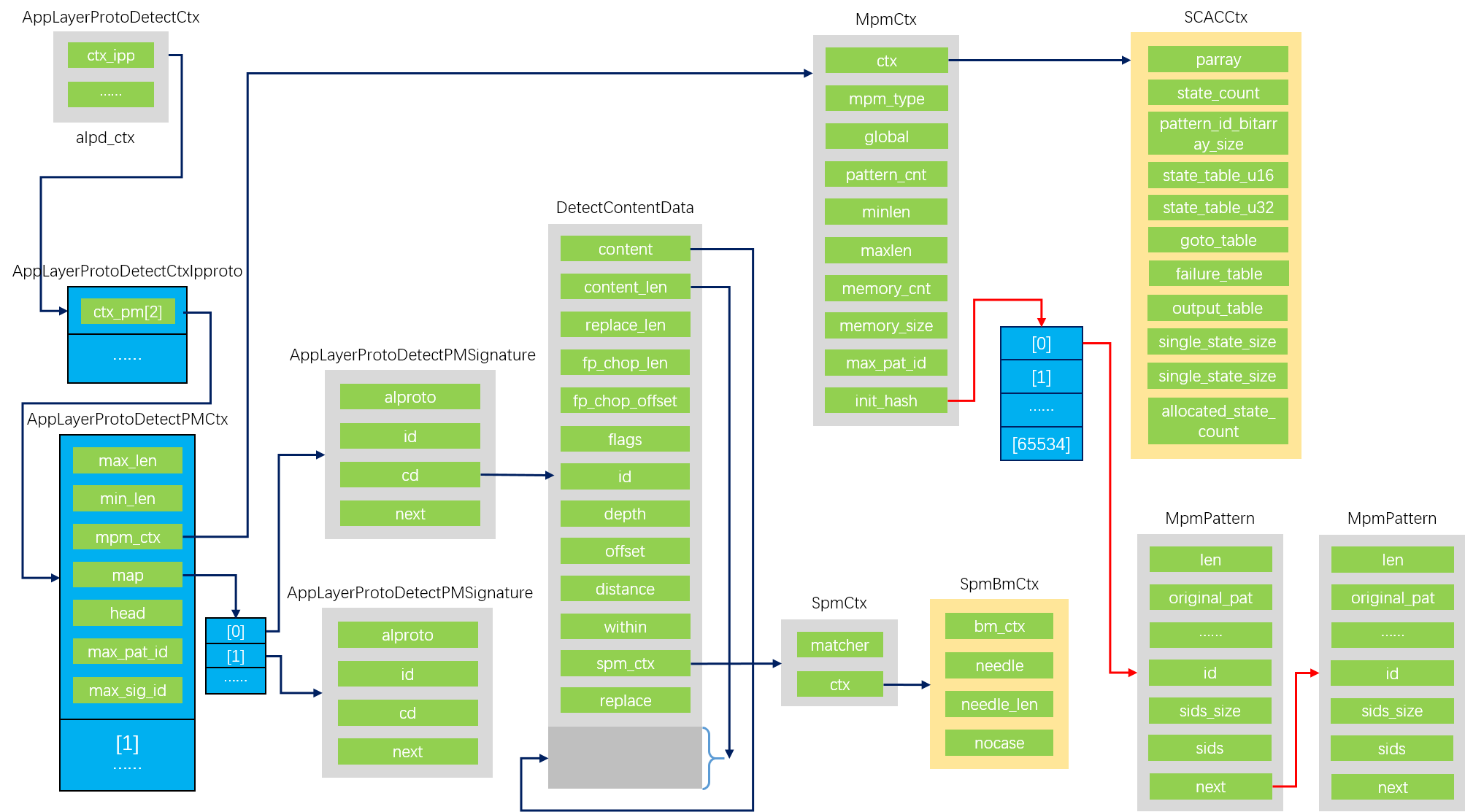
1 | typedef struct MpmCtx_ { |
1 | typedef struct MpmPattern_ { |
AppLayerProtoDetectPMPrepareMpm
这个函数功能为mpm算法预处理。直接调用mpm算法的Prepare函数指针。AC算法中实际调用为SCACPreparePatterns,以下为其实现。
- mpm_ctx成员ctx指针在AppLayerProtoDetectSetup中已经分配过了SCACCtx大小的内存。
- ctx成员parray指针分配内存,内存大小为模式数量个指针。
- 遍历mpm_ctx成员init_hash哈希表中的所有MpmPattern实例,并将parray指针数组中的每个指针依次指向MpmPattern的每个实例,parray指针数组的索引没有实际意义。在遍历过程中断开MpmPattern实例的next链表。遍历结束后释放init_hash的内存。
- ctx成员single_state_size设置为1024,这个数字的来源为256个32位整形数,占用空间1024字节。
- ctx成员pid_pat_list分配内存,使其指向一个数组,数组的每一项是一个SCACPatternList实例,数组的大小为模式最大id加一,也就是说以模式id为索引可以在这个数组中直接定位该模式。
- 遍历parray中的每个模式,根据模式id,将MpmPattern结构中的成员sids_size赋值给pid_pat_list相应的项,sids内存地址赋值给pid_pat_list相应的项。如果模式大小写敏感,为pid_pat_list的成员cs分配内存并将原始模式串拷贝过去,并设置模式长度。最后pid_pat_list中保存了所有模式的所对应的特征id和特征id数量,以及大小写敏感模式的原始串和长度。
- 调用SCACPrepareStateTable预处理AC算法的状态表。
- 释放parray数组指向的所有MpmPattern。
- 释放parray内存。
- 设置ctx成员pattern_id_bitarray_size为
(mpm_ctx->max_pat_id / 8) + 1,这个值标明了为所有模式id做一个位图所需要的字节数,在mpm模式匹配查找时会使用到。
1 | /** |
SCACPrepareStateTable中调用各函数逻辑如下,可以参考之前AC自动机多模式匹配:
SCACInitNewState
这个函数用于扩充goto_table和output_table,并且对goto_table中新增的项初始化。当allocated_state_count不大于state_count时,设置allocated_state_count从256开始每次乘2,然后依据此数量扩充goto_table(每项大小为single_state_size)和output_table(每项大小为sizeof(SCACOutputTable))的内存。内存扩充完成后,初始化goto_table中新增的状态(一维为state_count,二维从0到255,二维这里理解为一个字节的所有可能值)为SC_AC_FAIL。state_count自增一。SCACDetermineLevel1Gap
这个函数做了从初始0状态根据模式0偏移位字节输入后跳转的状态表,中间会多次调用SCACInitNewState用于扩充状态表,并填充goto表0状态的下一个跳转状态(一维为0,二维为一个字节的所有可能值,值为新增的跳转状态值),如果一个字节的可能值未在模式0偏移字节中出现则忽略该状态。SCACCreateGotoTable
这个函数对parray中的每个模式调用SCACEnter(这里使用的是所有模式的小写,也就是忽略大小写的模式),然后对goto_table中0状态后续跳转为SC_AC_FAIL的都修改为跳转到0状态。
SCACEnter
这个函数做的就是将输入的模式加入goto_table。先按顺序走过模式在表中已经存在状态值的前缀字节,知道遇到后续状态为SC_AC_FAIL的字节,然后对模式后续的每个字节调用SCACInitNewState扩充状态并更新goto_table中对新状态的跳转。然后调用SCACSetOutputState将该模式的最后状态和模式id加入output_table,output_table结构很简单,记录了该状态下有几个模式匹配完全以及每个模式的id。SCACCreateFailureTable
这个函数创建了所有状态的失败跳转。
为failure_table分配内存。
扫描goto_table的0号状态表的所有字节值,如果下一个状态不为0说明该字节值存在下一个状态节点,将状态值入栈,同时failure_table中该状态对应的跳转置为0,这一步的含义是首层节点的失败跳转都是根节点。
failure_table代表的失败状态跳转其实就是寻找到当前节点的最长公共后缀节点,为了达到最长的目的,需要广度优先逐层遍历。由于根节点的失败跳转都是根自身,首层节点的失败跳转都是根节点,这两部分是显而易见的,因此后续层的节点经过广度优先遍历都可以找到自己的最长公共后缀节点,也就是failure_table的填充。
递归的思路是,当前节点的最长公共后缀节点T不确定,但T一定满足一个条件,即T的最后一个路径字节与当前节点父节点到当前节点的路径字节相同,那么只要找到父节点的公共最长后缀节点TF,并且TF存在这个特定字节路径的子节点既可,这时TF的那个子节点就是当前节点的最长公共后缀节点T,即当前节点failure_table的跳转。如果TF没有那个特定字节路径,那么继续往回寻找TF的最长公共后缀节点TTF,直到找到合适的节点T或者根据父节点的failure_table逐步转到了根节点(到根节点说明完全没有最长公共后缀,那么当前节点的失败跳转也就是根节点了)。由于根节点和首层节点的失败跳转是填充好的,因此递归可以达成。
在广度优先逐层遍历创建失败跳转表时,每个状态节点会将其失败跳转节点的output_table合并到自己的output_table中,因为最长公共后缀匹配的模式也是其匹配的模式。SCACCreateDeltaTable
SCACConstructBoth16and32StateTables这个变量好像在CUDA中才会开启。
根据状态数量是否小于32767判断是生成16位还是32位的状态表,state_table_u16、state_table_u32。依然是广度优先遍历节点,合并goto_table和failure_table,在这个过程中,SC_AC_FAIL的状态跳转全部转换为确定状态的跳转。SCACClubOutputStatePresenceWithDeltaTable
由于在上一步中将SC_AC_FAIL全部为正常的状态跳转,因此状态表中不再存在负值。这个函数使用了16位状态表的第16位和32位状态表的第25位存储一个标志位,标记output_table中相应的状态是否有匹配的模式。SCACInsertCaseSensitiveEntriesForPatterns
这个函数将大小写敏感的模式标记在output_table中。具体如下。
遍历output_table中的所有状态,检查各个状态中的所有pid在pid_pat_list是否是大小写敏感的。如果该模式是大小写敏感的,则将output_table中该pid最高位置1,用以标记这个模式是大小写敏感的。SCACShrinkState
因为SCACInitNewState函数中对goto_table和output_table是从256大小开始每次乘2,因此存在浪费的内存。这里已经完成了整个状态表的准备工作,因此将output_table内存缩减到恰当的大小(即state_count大小)。goto_table和failure_table在这个函数返回后会被释放。
协议检测 - Search
应用层协议检测入口函数为AppLayerProtoDetectGetProto,比较简单,可以看到分别使用了pattern match和probing parser两种方式进行协议检测,如果pattern match检测到了协议类型就不再进行后续检测了。
1 | AppProto AppLayerProtoDetectGetProto(AppLayerProtoDetectThreadCtx *tctx, |
pattern match
入口函数为AppLayerProtoDetectPMGetProto,主要匹配功能由调用mpm算法的Search函数指针完成。
- 在Search前会通过四层协议和检测方向确定一个AppLayerProtoDetectPMCtx结构体实例,上文提到过这个结构体成员max_len包含了该多模匹配上下文中所有模式的最大长度,这里将要搜索的buffer的长度限制为不超过该长度,个人理解这个操作意味着所有应用层协议检测的模式都是从协议数据流头部开始的,否则这个操作将会遗漏可能的匹配内容。
- 限制搜索长度后,调用Search函数指针。在AC算法中实际为SCACSearch,可以参考之前的文章,这个函数的返回值仅表示模式匹配到的次数,匹配到的模式经过位图去重后将模式关联的特征填充到PrefilterRuleStore中,这里的特征没有去重。
- Search返回后,如果有匹配结果,遍历PrefilterRuleStore结构体取得特征id,通过id在AppLayerProtoDetectPMCtx结构的map成员定位到特征结构体AppLayerProtoDetectPMSignature,调用函数AppLayerProtoDetectPMMatchSignature再次针对特征关联的模式做一次spm匹配检查,与多模匹配不同点在于这里针对特征关联模式的offset和depth再次切割了搜索buffer和搜索长度,然后调用spm算法的Scan函数指针完成spm匹配检查。
- 通过单模匹配的特征,将其关联的应用层协议用一个位图去重后填充到数组中,最后返回数组。如果可搜索buffer长度达到了该mpm上下文中模式最大长度,在返回前会对flow设置标记,标记该方向的pattern match已经完成,FLOW_TS_PM_ALPROTO_DETECT_DONE或FLOW_TC_PM_ALPROTO_DETECT_DONE。
1 | /** \brief structure for storing potential rule matches |
probing parser
入口函数为AppLayerProtoDetectPPGetProto。
- 确定需要检测的目的端口和源端口。
- 根据四层协议和端口号,对目的端口和源端口分别取得类型为AppLayerProtoDetectProbingParserPort的pp_port_dp和pp_port_sp,并取得相应的pe命名为pe1和pe2。
- 根据检测方向,取flow成员probing_parser_toserver_alproto_masks或probing_parser_toclient_alproto_masks的地址赋值给alproto_masks,这里成员的作用为与pe的alproto_mask对比标记哪些应用层协议经过检测不匹配,后续可以不再检测该应用层协议。
- 如果目的端口和源端口的pe都没有取到,则设置flow上该方向的probing parser完成,FLOW_TS_PP_ALPROTO_DETECT_DONE或FLOW_TC_PP_ALPROTO_DETECT_DONE。
- 对pe1和pe2做同样的操作。
- 检查buffer长度和pe的min_depth项,如果长度不足或alproto_masks中已经存在于该pe的alproto_mask相同的位,则不处理该pe,通过next指针开始检查pe链表的下一项。
- 根据方向调用不同的协议检查函数(是在probing parser注册时传入的),STREAM_TOSERVER对应pe成员ProbingParserTs函数指针,STREAM_TOCLIENT对应pe成员ProbingParserTc函数指针(在调用ProbingParserTc时并没有检查方向,个人认为应该是一个bug,但是实际运行环境由于前面有pattern match和probing parser对目的端口的识别,很难运行到这里而产生可见的错误),如果识别到了应用层协议则直接结束检查返回该协议号。如果函数指针调用返回ALPROTO_FAILED或buffer长度超过了pe成员max_depth(前提是max_depth不为0)则更新alproto_masks标记该应用层协议识别失败以后也不用检查该协议。
- 经过对两个端口上pe链表的遍历,如果alproto_masks包含了所有的alproto_mask(当buffer长度不足时,会不检查该pe,从而缺少某些alproto_mask)说明检查了所有的pe但是没有匹配的,因此标记flow该方向已经完成probing parser,标记为FLOW_TS_PP_ALPROTO_DETECT_DONE或FLOW_TC_PP_ALPROTO_DETECT_DONE。
UDP应用层协议检测
UDP协议上的应用层协议检测比较简单,直接调用AppLayerProtoDetectGetProto,传入Packet的载荷payload和payload_len。调用位置为 FlowWorker -> AppLayerHandleUdp 。
TCP应用层协议检测
TCP协议上的应用层协议检测核心与UDP一样,都是调用AppLayerProtoDetectGetProto。区别在于检测方向的确定、检测函数调用位置、检测buffer的确定、双向数据流协议检测结果不一致时最终检测结果的确定。
检测方向
前文tcp reassembly记录过在处理tcp packet时,IDS模式和IPS模式(以及几种特殊情况)下应用层协议识别的方向是不同的。比如IDS模式下对相对方向的数据缓存做应用层协议识别,另外的情况对本方向数据缓存做应用层协议识别。
调用位置
TCP协议中应用层协议检测同样由函数AppLayerProtoDetectGetProto完成,调用位置在 AppLayerHandleTCPData -> TCPProtoDetect -> AppLayerProtoDetectGetProto。
但是由于TCP协议的多种状态和逻辑,AppLayerHandleTCPData会在多个位置被调用。
- StreamTcpReassembleAppLayer函数中,如果tcp segment都已经处理完毕,而且会话处于关闭状态或当前是一个超时伪造包,会调用AppLayerHandleTCPData,目的是向后续的应用层协议解析器传递STREAM_EOF标记。这里与协议检测无关。
- StreamTcpReassembleAppLayer函数在正常条件下会调用进入ReassembleUpdateAppLayer函数。
- 在缓存数据存在GAP的情况下,会调用AppLayerHandleTCPData,将GAP长度和标记STREAM_GAP传递给应用层协议解析器。在这个流程里,如果应用层协议之前没有检测到,则会直接将stream标记为协议检测已完成STREAMTCP_STREAM_FLAG_APPPROTO_DETECTION_COMPLETED。这个标记的影响是,在后续调用AppLayerHandleTCPData时参数标记中将不再包含STREAM_START,这会使程序不再进入TCPProtoDetect函数,因此将不会进行协议检测。
- 正常缓存数据情况下调用AppLayerHandleTCPData。
- 在缓存数据存在GAP的情况下,会调用AppLayerHandleTCPData,将GAP长度和标记STREAM_GAP传递给应用层协议解析器。在这个流程里,如果应用层协议之前没有检测到,则会直接将stream标记为协议检测已完成STREAMTCP_STREAM_FLAG_APPPROTO_DETECTION_COMPLETED。这个标记的影响是,在后续调用AppLayerHandleTCPData时参数标记中将不再包含STREAM_START,这会使程序不再进入TCPProtoDetect函数,因此将不会进行协议检测。
ps:StreamTcpReassembleAppLayer函数开始会检查会话的STREAMTCP_FLAG_APP_LAYER_DISABLED标记与stream的STREAMTCP_STREAM_FLAG_NOREASSEMBLY标记,任意一个标记的存在会导致函数直接返回。STREAMTCP_STREAM_FLAG_NOREASSEMBLY是在FlowWorker的最后segment清理阶段如果发现STREAMTCP_STREAM_FLAG_DEPTH_REACHED标记存在而添加的。
检测数据
上面介绍了正常数据缓存情况对AppLayerHandleTCPData的调用是与应用层协议检测有关的。当处于IDS模式且该数据包不是超时伪造包时,检测数据长度只会取已经ack过的数据部分。其他情况不受ack影响。
在AppLayerHandleTCPData返回0且stream中标记应用层协议检测已经完成时(STREAMTCP_STREAM_FLAG_APPPROTO_DETECTION_COMPLETED),stream成员app_progress_rel增加该次处理的数据长度,记录数据中已经经历过应用层协议检测和解析的数据数据。
ps:上文缓存数据存在GAP的情况下,调用AppLayerHandleTCPData后也会为stream成员app_progress_rel增加GAP的长度。因为由于GAP的存在应用层协议检测也已经结束了,而且解析器也接受了GAP的存在,也就是说相应长度部分的应用层处理已经完成。
检测结果
AppLayerHandleTCPData中有两处调用TCPProtoDetect
- 应用层协议已知,但是flow存在标记FLOW_CHANGE_PROTO。这里是协议变更流程,后续还有一些操作,暂时不关注。
- 应用层协议未知,参数flags中包含STREAM_START,这个标记意味着应用层协议检测未完成。
TCPProtoDetect中对当前方向缓存数据调用AppLayerProtoDetectGetProto。
- 首先flow中alproto_ts和alproto_tc两个成员记录两个方向分别独立做应用层协议检测的结果。
- 如果检测到当前方向应用层协议
- 如果对端有检测结果,且检测结果与当前方向不一致。
- 如果当前会话数据已经经过了协议解析器,那么alproto跟随对向的协议结果。
- 如果当前会话数据没有经过协议解析器,那么alproto跟随server发出的数据的协议检测结果,也就是与STREAM_TOCLIENT方向的检测结果一致。
- 如果对端无检测结果,或检测结果与当前方向一致,设置flow成员alproto为当前检测结果。
- 标记当前stream已完成应用层协议检测,标记STREAMTCP_STREAM_FLAG_APPPROTO_DETECTION_COMPLETED。
- 根据应用层协议,更新session会话的reassembly_depth。
- 更新flow标记当前方向应用层协议检测,FLOW_PROTO_DETECT_TS_DONE或FLOW_PROTO_DETECT_TC_DONE。(这是IDS模式下的逻辑,IPS下逻辑暂时不关注)
- 检查如果对端方向的数据是先发出的,那么先将对端缓存数据放入应用层解析器中。个人理解为确保请求响应数据解析的时序性。
- 如果当前会话数据未经过协议解析器,而且应用层协议有要求数据首先发出的方向(这个方向保存在应用层协议分析的全局变量alp_ctx内部),且这个方向与检测到的方向不符,意味着检测出错,关闭应用层检测和解析,返回-1。
- 如果当前会话数据未经过协议解析器,而且应用层协议有要求数据首先发出的方向,且这个方向与当前方向不符,意味着对端数据还有被ack,这时清理掉flow和stream上关于协议检测的相关标记,返回-1。等待对端数据做协议检测。
- 设置会话数据已经经过协议解析器(session会话成员data_first_seen_dir设置为APP_LAYER_DATA_ALREADY_SENT_TO_APP_LAYER)。
- 调用协议解析函数AppLayerParserParse。
- 如果对端有检测结果,且检测结果与当前方向不一致。
- 如果未检测到当前方向应用层协议
- 如果这个会话是一个midstream会话,并且不是从synack包开始的。那么检查client发出的数据(也就是STREAM_TOSERVER方向),如果pattern match和probing parser都已经完成,则关闭应用层协议检测和解析并返回0。因为suricata在mistream时只信任完整的request数据,如果request没有检测到应用层协议,那么视为数据不完整,不继续做检测和解析。
- 如果对端检测到应用层协议。
- 如果当前会话数据未经过协议解析器,而且对端的检测到的协议要求了数据首先发出的方向,且这个方向与当前方向不符,关闭应用层协议检测和解析,返回-1。
- 这里后续的逻辑很奇怪,没懂TODO。
- 如果对端同样未检测到应用层协议。调用TCPProtoDetectCheckBailConditions检查是否需要放弃应用层协议检测和解析。
- 如果两端的PM和PD都完成了,那么关闭应用层协议检测和解析。
- 如果一端的PM和PD完成了,同时该方向的缓存数据大于100k,而且相对方向缓存数据为0,那么关闭应用层协议检测和解析。
- 如果一端的PM和PD完成了,同时该方向的缓存数据大于100k,相对方向缓存数据不为0,相对方向PP完成但是PM未完成,那么关闭应用协议检测和解析。
- 最后这个条件很奇怪,没懂。server发出的数据大于100k,且该方向的PM和PD都未完成,对端PM未完成、PD完成。那么关闭应用层协议检测和解析。